
| 일 | 월 | 화 | 수 | 목 | 금 | 토 |
|---|---|---|---|---|---|---|
| 1 | ||||||
| 2 | 3 | 4 | 5 | 6 | 7 | 8 |
| 9 | 10 | 11 | 12 | 13 | 14 | 15 |
| 16 | 17 | 18 | 19 | 20 | 21 | 22 |
| 23 | 24 | 25 | 26 | 27 | 28 | 29 |
| 30 |
- typescript
- ChatGPT
- 자료구조
- Generics
- 비주얼 스튜디오 코드
- Schema Registry
- html
- nestjs
- Certbot
- Express
- python
- stream
- Linux
- V8
- ES6
- nodeJS
- Functional Programming
- node.js
- 함수형프로그래밍
- NPM
- MSA
- vscode
- https
- Let's Encrypt
- 파이썬
- javascript
- GIT
- 알고리즘
- docker
- MSK
- Today
- Total
JangBaGeum.gif
[Go] goroutine은 어떻게 작동하는가: 왜 빠르다는 건데? 본문
Go 언어를 사용하지 않아도 goroutine이라는 단어는 한 번쯤 들어봤을 것 같다.
"가볍다", "수십만 개도 문제없다", "스레드보다 효율적이다" 같은 말이 항상 따라 나온다.
그런데 실제로 goroutine이 어떻게 동작하길래 이련 평가를 받는가 라는 궁금증이 생겼다.
나는 Go 언어를 사용하는 개발자는 아니다. 하지만 주로 사용하지 않는 언어 혹은 기타 기술들의 동작 원리와 녹아있는 방법론, 사상을 공부하는 것은 늘 영갑을 주고 실제 개발을 할 때 적용할 수 있는지 고민하는데 정말 큰 도움을 준다.
특히 goroutine처럼 기존 병렬성 개념을 재해석한 구조를 깊이 들여다보면, 언어를 넘어서 시스템 설계나 성능 최적화에 대한 감각을 키우는 데에도 큰 도움이 될 것 같았다.
이번 글에서는 goroutine이 어떻게 작동하고, 왜 그렇게 설계되었고, 실제 어떤 방식으로 메모리와 스레드를 사용하는지를 기록하며 설명하려고 한다.

1. goroutine 이란?
goroutine은 Go 언어에서 함수를 병렬로 실행하는 단위이다.
다른 언어의 스레드와 유사하지만, 훨씬 가볍고 런타임 수준에서 독자적을 관리된다.
- 재밌게도 `go` 키워드만 붙이면, 어떤 함수든 goroutine으로 실행된다.
- OS의 스레드보다 적은 메모리를 사용한다.
- 수만 개를 만들어도 안정적으로 작동할 수 있다고 한다.
2. 어떻게 가볍게 작동할 수 있는가?
Go 런타임의 고유한 M:N 스케줄링 구조와 동적 스택 할당 메커니즘의 역할이 크다고 한다.
여기서 말하는 M:N 스케줄링은 "M가의 사용자 수준의 실행 단위(goroutine)를 N개의 커널 수준의 실행 단위(OS 스레드) 위에 Go 런타임이 직접 스케줄링해 매핑하는 방식"을 의미한다.
메커니즘의 구성 요소는 크게 아래와 같다.
| 구성 | 설명 |
| G (goroutine) | 우리가 만든 실행 단위. 함수를 실행하는 컨텍스트 (t사용자 수준의 실행 단위) |
| P (Processor) | 실행 가능한 goroutine 자원을 관리하는 논리적 유닛 |
| M (Machine) | 실제 OS 스레드, G를 CPU에 올리는 일꾼 |
"P"는 goloutine의 실행 큐를 관리하며 스케줄링 및 자원 할당을 담당한다.
"P"는 실행을 기다리고 있는 goroutine들의 로컬 큐를 관리한다. 이 큐에는 아직 M에 의해 실행되지 않은 goroutine들이 들어있다. "P"는 자신의 로컬 큐에 있는 goroutine을 M에 할당하여 실행한다. "P"는 또한 다른 "P"의 큐에서 G를 훔쳐오기를 통해 균형을 맞춘다.
런타임은 G -> P -> M 구조로 goroutine을 관리하며, OS 스레드 수보다 훨씬 많은 goroutine을 동시에 운용할 수 있다.
간단한 구조는 아래와 같다.
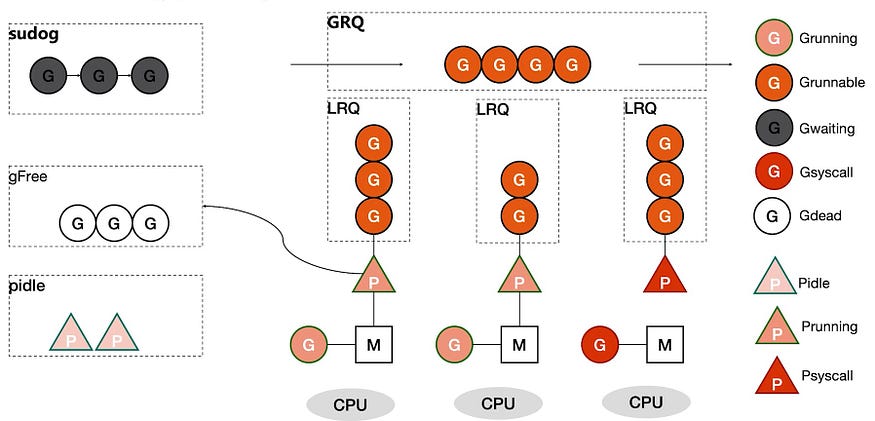
| 구성 | 설명 |
| LRQ (Local Run Queue) | 각 P가 자체 관리하는 작업 대기열이다. P와 연결된 M은 해당 LRQ에 있는 goroutine을 가져와 실행한다. |
| GRQ (Global Run Queue) | 모든 P가 공유하는 큐이다. P는 자신의 LRQ가 비게 되면 GRQ에 있는 goroutine을 자신의 LRQ에 넣는다. GRQ에는 LRQ에 속하지 않는 G들이 존재하고 G가 LRQ에 소속되지 않는 이유는 다양하다. |
2.2. goroutine의 병렬성은 어떻게 관리될까?
위 구성들로 확인했던 것과 같이. Go의 병렬성은 OS 스레드가 아닌 Go 런타임이 직접 관리하는 스케줄러에 의해 이루어진다.
- 각 P는 자신의 goroutine 큐를 관리한다.
- M이 P로부터 goroutine을 받아 실행
- P가 일이 없으면 다른 P로부터 goroutine을 훔쳐오는 구조 가짐
- I/O 등으로 goroutine이 블로킹되면, 다른 M이 남은 작업을 처리
구조는 대충 알았으나 이러한 구조가 왜 goloutine을 가볍게 운용할 수 있도록 했을까?
이유는 아래에서 설명한다.
2.2.1 OS 스레드를 직접 만들지 않는다.
전통적인 언어에서는 병렬 처리를 위해 OS 스레드를 만들어야 했다.
- 하나 만들면 보통 1MB 이상의 고정 스택 메모리가 필요
- 콘텍스트 스위칭은 커널 수준에서 무겁게 일어남
반면 Go는:
- goroutine이 OS 스레드에 직접 묶이지 않고, Go 런타임이 자체 스케줄러를 통해 다수의 goroutine을 적은 수의 OS 스레드로 실행
2.2.2. 스택을 작게 시작하고, 필요할 때만 키운다.
goroutine은 2KB의 스택 메모리로 시작한다. 만약 부족하면 스택을 자동으로 확장한다.
2.2.3. 유저레벨 스케줄링으로 context switching이 빠르다.
goroutine 사이의 전환은 OS가 아니라 Go 런타임이 직접 수행한다.
- OS 스레드처럼 커널에 개입을 요청하지 않고, Go 런타임이 G를 P에 넣고 M이 꺼내서 실행
이 구조는 다음과 같은 효과를 준다고 한다.
- 락 없는 로컬 큐 처리 (LRQ)로 빠른 작업 처리
- 글로벌 큐 (GRQ)로 작업 불균형 해소
- Work Stealing으로 유효 P가 다른 P의 goroutine을 실행 가능
결과적으로 수천수만 개의 goroutine이 적은 스레에서 유기적으로 잘 돌아가는 병렬 처리 환경이 만들어진다고 한다.
3. goroutine의 스택은 왜 2KB밖에 안 될까?
위에서 언급되었지만 기존 OS 스레드는 1MB 이상의 스택을 미리 예약한다.
그에 비해 goroutine은 시작 시 단 2KB의 스택을 사용한다고 한다.
그 이유는 go가 스택을 필요할 때만 동적으로 키우는 구조로 설계되었다.
3.1. 동작 방식 (Stack Split)
1. goroutine은 2KB의 작은 스택으로 시작
2. 함수 호출이 깊어지거나 지역 변수가 많아져 스택이 부족하면,
3. Go 런타임은 새로운 더 큰 스택을 힙에 할당하고, 기존 스택의 내용을 복사한다.
4. 함수 실행을 새 스택에서 계속 이어간다.
여기서 드는 의문, 스택 복사는 동작의 지연을 유발하지 않을까?
4. 스택 복사는 느리지 않을까?
Go의 stack split은 현실적으로 문제가 되지 않는다고 한다. 이유는 아래와 같다.
실제로는 대부분 확장되지 않는다.
- 대부분의 goroutine은 짧고 단순한 함수 실행만 포함하므로, 2KB 스택으로 충분하다.
스택 복사는 빠르다.
goroutine 스택은 연속된 메모리 블록이기 때문에, 복사 연산이 매우 빠르고 CPU 캐시 친화적이다.
shrink도 가능하다.
어느 시점의 Go 버전 이후부터는 늘어난 스택 메모리를 GC 타이밍에 자동으로 줄어들기도 한다고 한다.
5. goroutine은 언제 확장될까?
아래와 같은 상황에서 stack split이 발생할 수 있다:
- 깊은 재귀 호출
- 큰 지역 배열 선언
- 함수 call chain이 길어질 때
이 경우 어셈플리 코드 수준에서 함수의 시작 시점에서 스택의 여유를 판단하는 코드가 삽입되어 부족한 경우 스택 확장 + 복사를 수행하고, 이후 새 스택에서 다시 함수 진입을 시작한다.
6. 그래서 goroutine이 왜 좋은가?
간단하게 정리하면 goroutine은 단순히 "작은 스레드"의 운용이 아닌 자체가 하나의 런타임 시스템이며 아래와 같은 특징이 있다고 할 수 있을 것 같다.
| 항목 | 설명 |
| 가벼운 메모리 사용 | 시작 시 2KB -> 필요 시만 확장 |
| 자동 스케줄링 | M:N 구조 + work stealing |
| 수십만 개 실행 가능 | OS 스레드보다 메모리 부담 적음 |
| 고성능 | 대부분의 goroutine은 확장 없이 실행되며, 복사도 빠름 |
| 개발자 경험 | `go func()` 하나로 병렬 처리 가능, 간결함 |
goroutine은 단지 성능 좋다로 끝나는 것이 아니라, Go 언어가 지향하는 단순함, 병렬성, 안정성 등의 철학을 잘 보여주는 대표 사례인 듯하다.
물론 그 내부에는 스케줄러, 메모리 관리, 어셈블리 최적화 등 복잡한 기술이 숨어있지만, 개발자는 이를 알지 못해도 아주 쉽게 병렬 프로그램을 만들 수 있다. 이러한 구조를 이해하고 나면, Go를 쓰지 않더라고 goroutine이 제시하는 방식은 다른 언어에서 병렬성을 설계하거나 효율적인 런타임 구조를 고민할 때 깊은 영감을 줄 수 있을 것 같다.
내가 주로 사용하는 Node.js는 이벤트 루프, 비동기 콜백 등의 개념을 포함하여 싱글 스레드로 동작하고 있다. Go와 비교했을 때, 병렬성 문제를 서로 전혀 다른 철학으로 풀고 있다는 점이 인상 깊었고 중요한 부분이 아닐까 싶다.
참고
(블로그) goroutine 설계 관련 - https://go.dev/blog/concurrency-is-not-parallelism
(블로그) goroutine 스케줄링 관련 - https://www.ardanlabs.com/blog/2018/08/scheduling-in-go-part2.html
(github) goroutine 구조체 - https://github.com/golang/go/blob/master/src/runtime/proc.go